Ollama本地运行LLM教程
Ollama是一个开源的 LLM服务工具,可以非常便捷地下载和运行本地大模型应用。
1. Ollama简介
Ollama是一个开源的 LLM服务工具,可以非常便捷地下载和运行本地大模型应用。
2. Ollama的安装和配置
在Ollama官网可以直接下载安装程序,点击即可安装。  安装完成有些环境变量最好进行一下配置,不然就会按照其默认值运行大模型。特别是在Windows下,拉取大模型都是默认在C盘目录下,特别占用空间。
安装完成有些环境变量最好进行一下配置,不然就会按照其默认值运行大模型。特别是在Windows下,拉取大模型都是默认在C盘目录下,特别占用空间。
- OLLAMA_MODELS:模型文件存放目录,默认目录为当前用户目录(Windows 目录:
C:\Users%username%.ollama\models,MacOS 目录:~/.ollama/models,Linux 目录:/usr/share/ollama/.ollama/models),如果是 Windows 系统建议修改(如:D:\OllamaModels),避免 C 盘空间吃紧 - OLLAMA_HOST:Ollama 服务监听的网络地址,默认为127.0.0.1,如果允许其他电脑访问 Ollama(如:局域网中的其他电脑),建议设置成0.0.0.0,从而允许其他网络访问
- OLLAMA_PORT:Ollama 服务监听的默认端口,默认为11434,如果端口有冲突,可以修改设置成其他端口(如:8080等)
- OLLAMA_ORIGINS:HTTP 客户端请求来源,半角逗号分隔列表,若本地使用无严格要求,可以设置成星号,代表不受限制
- OLLAMA_KEEP_ALIVE:大模型加载到内存中后的存活时间,默认为5m即 5 分钟(如:纯数字如 300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活);我们可设置成24h,即模型在内存中保持 24 小时,提高访问速度
- OLLAMA_NUM_PARALLEL:请求处理并发数量,默认为1,即单并发串行处理请求,可根据实际情况进行调整
- OLLAMA_MAX_QUEUE:请求队列长度,默认值为512,可以根据情况设置,超过队列长度请求被抛弃
- OLLAMA_DEBUG:输出 Debug 日志标识,应用研发阶段可以设置成1,即输出详细日志信息,便于排查问题
- OLLAMA_MAX_LOADED_MODELS:最多同时加载到内存中模型的数量,默认为1,即只能有 1 个模型在内存中
我自己配置的只有OLLAMA_MODELS这一项,直接在用户变量添加就可以了,需要重启一下Ollama。 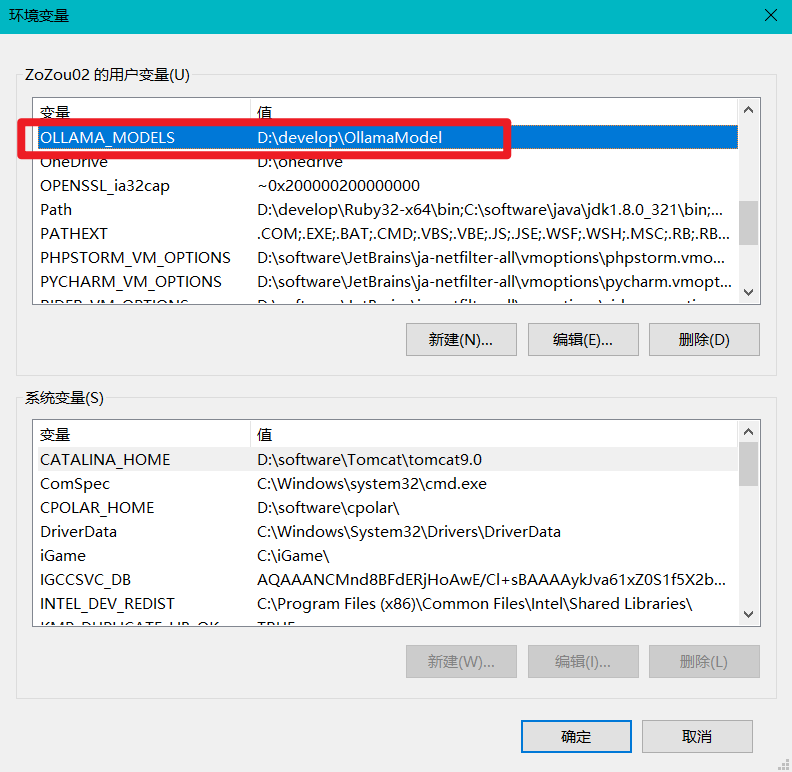 安装成功并且点击运行后,Windows任务栏会有一个羊驼标志。
安装成功并且点击运行后,Windows任务栏会有一个羊驼标志。 
3. 使用命令行下载并运行开源的LLM
打开命令行工具,使用命令即可操作Ollama。 ollama list显示本地大模型列表
1
2
3
4
PS D:\> ollama list
NAME ID SIZE MODIFIED
qwen2:latest e0d4e1163c58 4.4 GB 22 hours ago
qwen2:7b e0d4e1163c58 4.4 GB 22 hours ago
ollama run 本地大模型名称运行本地模型
1
2
PS D:\> ollama run qwen2
>>> Send a message (/? for help)
ollama pull qwen:7b从Ollama的仓库拉取模型 本pull命令从 Ollama 远程仓库完整下载或增量更新模型文件,模型名称格式为:模型名称:参数规格;如ollama pull qwen2:7b 则代表从 Ollama 仓库下载qwen2大模型的7b参数规格大模型文件到本地磁盘: 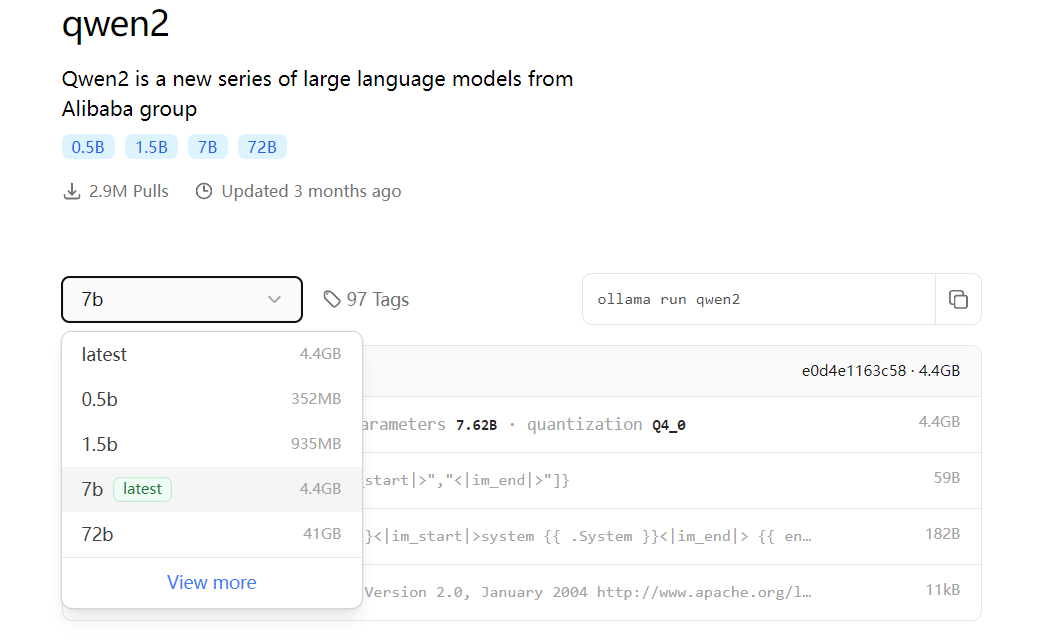 如果没有指定版本,则会下载带有
如果没有指定版本,则会下载带有latest标识的版本。
4. 开源图形界面
开源项目:ollama-webui-lite
git clone该项目到本地。- 到项目目录下使用
npm install安装依赖。 - 使用
npm run dev运行项目。 - 使用浏览器打开:http://localhost:3000/
5. ollama与springboot结合
…..
6. Windows下如何让Ollama的模型使用GPU
7. 运行Huggingface下载的模型
8. 参考资料
This post is licensed under CC BY 4.0 by the author.